句法分析相关研究
句法分析主要用于在深层次上处理分析语言的内在结构,其中许多分析模型(比如句法树模型和短语语块识别模型)在许多的实际生产系统中得到广泛应用。
语法是语言学中专注于分析词语的某种特定用法或者词语间相互关系的一门学科,可以将其更细致的划分为词法和句法。其中前者的研究方向主要是分析词语的组合结构与变化方式, 后者的则更专注于分析词语是如何组合成句子。
句法分析是指依据某种自然语言的相关语法规则,对给定句子分析其中的词语语法功能,并识别出相应的语法结构。我们从以下两点来分析思考:
- 怎样合理的定义一套符合语言学的语法规则,该规则必须是一种可以在计算机中方便表示和处理的描述规范。这就必须通过高度抽象的符号公式对句子进行理论上的研宄和表述。
- 如何根据给定的语言符号描述规范,对正常的自然语言句子进行句法分析, 并合理的表示出分析结果。
相关语法理论
采用抽象的语言符号来形式化的表示自然语言的语法结构可以有效的、更直观的分析句子更底层的结构特点。成分语法和依存语法都是从上面的角度出发研宄句子的结构, 成为比较主流的研究分析方法。
成分语法独有的特点是用树形图以层次化的方式分析、表达句子的语法成分。常用的语法成分包括: Predicate谓语成分、 Object宾语成分)、 Attribute定语成分)、 Subject主语成分)、 Complement补语成分)和 Adverbial状语成分)。例如句子“我上课迟到了” , 其中“我”是主语, “上课"是谓语, “迟到了”是补语。 图是句子"那有一个逼真的木头人"的图形化成分语法表示。
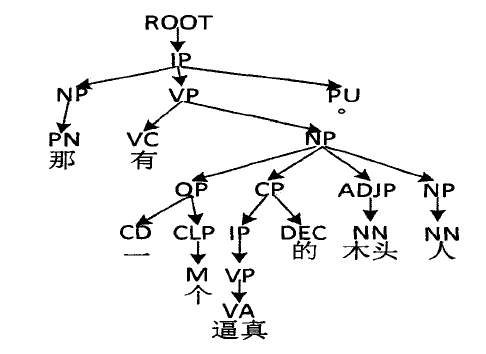
句法分析在实际应用中除了处理自然语言外,还用于处理(像 html语言、xml语言)等网络应用语言。对于成分语法,其主要使用Chomsky文法来处理自然语言, 以形式语言为基础来分析句子语法成分。
形式语言是按照以特定规律组成的描述符号序列或字符序列,与形式文法相对应,形式文法是用来规定句子的组成结构是否符合特定语言的使用规则的一种格式, 该格式可以作为将词语生成句子的准则。 比较典型的形式语法模型是由Chomsky在1959年提出的一种描述自然语言的理论模型。
典型的形式文法G由{P, S, VT, VN}四个部分组成,而且需要满足如下规则:


Chomsky将文法分成四类: 0型文法、 1型文法、 2型文法和 3型文法。
- 0型文法(短语语法), 其描述能力与图灵机相当。
- 1型文法(上下文有关文法), 其描述能力与线性界限自动机相当。
- 2型文法(上下文无关文法), 其描述能力与非确定下推自动机相当。
- 3型文法(右线性文法), 这种文法与正规式等价, 属于正规语法。
依存语法是研宄比较多、发展比较快的另一种主流的语法结构分析方法,其基本的出发点是分析句子所包含的词语组合之间的相互关联,通过分析这些关系来理解句子的内在含义,反映到句子表层的语法结构上。这种关联关系和成分语法是有区别的, 依存语法中词语之间直接具有相互依存关系, 组成依存关系对, 不存在非终节点。依存关系对中具有描述说明性质的词语称为修饰词(从属词) , 而占据主导地位的名词或动词称为支配词。在依存语法中,修饰与支配的关系显然不是对称的,可以用有向图的方法来表示这种关系结构。依存关系对中修饰词与支配词之间的关系有以下特点:
- 修饰词与支配词是 对应的,一个修饰词不能修饰多个支配词。
- 支配词的作用范围没有限定, 一个支配词可以有多个修饰词修饰。
需要注意的是修饰词的角色并不是一成不变的,它可以作为句子中其他词语的支配词,同样支配词也可以是其他词语的修饰词,句子中这种支配关系是首尾交替的, 最后归结于Root核心词,这些相互交织的关系网整体称为依存树。
核心词是句子中依存关系的根节点,一般作为句子中的谓语,主要表达主语 “是什么”、“做什么”的状态。所有依存对都有各自的依存关系类型,表明不同的修饰关系, 比较典型的有“状语”、“定语”等。
语言学研究中一直没有给出判定依存关系的规则, 本文以 Hudson总结的依 存关系确定方法为参考 。设依存关系结构用C表示,支配词用 H表示,修饰词用 M表示, 则具体准则如下:
- H有时可以取代 C, 并决定 C的语法、语义类型
- M在语义上对 H做了限制, 其中 M是可以省略的, 但 H是必须的
- M是必须的还是可以省略的是由 H决定的
- M有很多不同的形式, 选用哪种形式由H决定的
- H和 M在句子中的相对位置是由H决定的
上面的标准从语义和语法的角度给出了关于依存关系的定义,但是要给出一个符合所有情况的依存关系标准是比较困难的。许多学者认为要区分研究不同种类的依存关系。

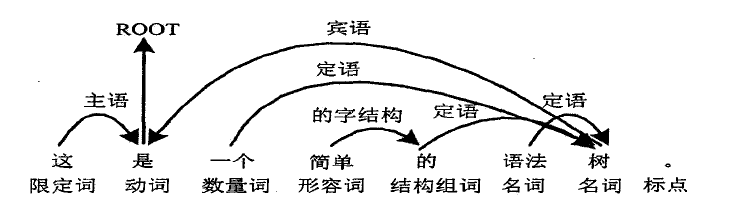
用依存关系树表示如下图:

谓宾关系和主谓关系在句子中的依存关系是比较明显的,而有一些依存结构就不太容易定义依存关系, 这些结构主要有:
- 包含如结构助词、连词等功能词的结构,对于这些功能词的依存关系的判定, 不同的算法有所区别
- 语义元素为并列形式的并列结构, 它们之间不存在明显的依存关系。对于这种结构, 不用的理论假设和处理策略不同, 结果也有不同。
在目前基于统计方法的句法分析方法中,依存句法有着自己独特的优势,越来越受到研宄学者的青睐。其优点主要体现在:首先依存句法形式简单,易于表示和实现,词典标注简单。其次很容易基于依存句法构造高精度、高效的处理工具包,编程上容易实现。
句法分析方法
对于成分句法分析,研究学者们提出了很多简单有效的分析方法,比如分析法、自底而上分析法等。但是这些算法在处理自然语言歧义时的表现不尽如人意。近几年研究学者们从概率的角度对该算法也做出了一些改进,一种是增加概率因素处理文法分析中的相关规则;另一种是基于第一种方法进一步细化中心词对概率的影响。
所有这些研宄方法的目标都是一致的,就是着力于构建一个对于任意一个句子都能够分析出有用的合理的语法结构的系统,即句法分析器。如果在句法分析中增加概率因子,则有三种算法改善方式:第一种方法是利用概率提高语法分析的效率,即在不影响结果质量的前提下,对其搜索空间进行剪枝或排序,缩短找到最优的分析路径的时间;第二种方法是在所有可能的处理结果集中蹄选出概率最高的结果;第三种是将句法分析器当作构建于所有词语之上的网络模型,该模型可以分析出网络中具有最大概率的词语序列。
依存文法分析较成分语法分析具有一定的优势,是目前研宄分析句法的主流算法。基于数据的分析方法和基于句法的分方法是目前研究依存语法中常用的两种分词方法。由于第二种方法是在给定文法定义的基础上分析句子的,所以目前主要的研究集中在第一种方法。基于数据驱动分析方法包含下面三个过程:
- 构建模型, 主要研究怎样对输入句子中的依存结构进行打分
- 参数估计, 主要研究如何通过标记数据对上一步构建的模型做参数估计
- 推断, 查找句子所有可能的依存结构中得分最高的结构
随着研宄的深入,数据驱动分析方法又细分为基于转换的分析方法和基于图的分析方法。第一种方法的典型研宄是MSTParser分析器,后一种方法的典型研究是MaltParser分析器。其中基于转换的分析方法主要是通过贪婪算法逐步判定词语之间的依存关系。首先根据输入的句子建立初始化状态,然后通过一个动作变化,将当前状态转化为另一个状态。转换到最后状态时,就形成了一颗完整的依存关系分析树。整个过程通过不同的算法来定义不同的状态和变换动作,其时间复杂度为O(n^2)左右,这种方法的效率比较高,因此也深受许多研究学者的喜爱。而基于图的分析方法,主要是通过者近似或者动态规划的算法来得到全局最优的满足依存关系约束的依存树,其时间复杂度最少为O(n^3),计算效率比转换的方法要差很多。