词性标注相关方法
现代汉语中通过词性来区分词语的类别, 常用的词性分为两大类:
实词: 代词、量词、数词、形容词、动词和名词。 虚词: 叹词、拟声词、助词、连词、副词和介词。
词性标注是指根据某种规则给句子中的词语标记出应有的词性。与英语语言不同, 中文语言中词性不会发生变化,但是中文词语有丰富的词性, 如“渴望” 在不同的应用场合可以作为名词, 也可以作为动词。汉语语言另外一个特性是, 在特定的语境上下文环境下,某个词语的词性是特定的,词性标注所要完成的工作就是在众多候选词性中针对当前语境选取最合适的词性。
词性标注规范
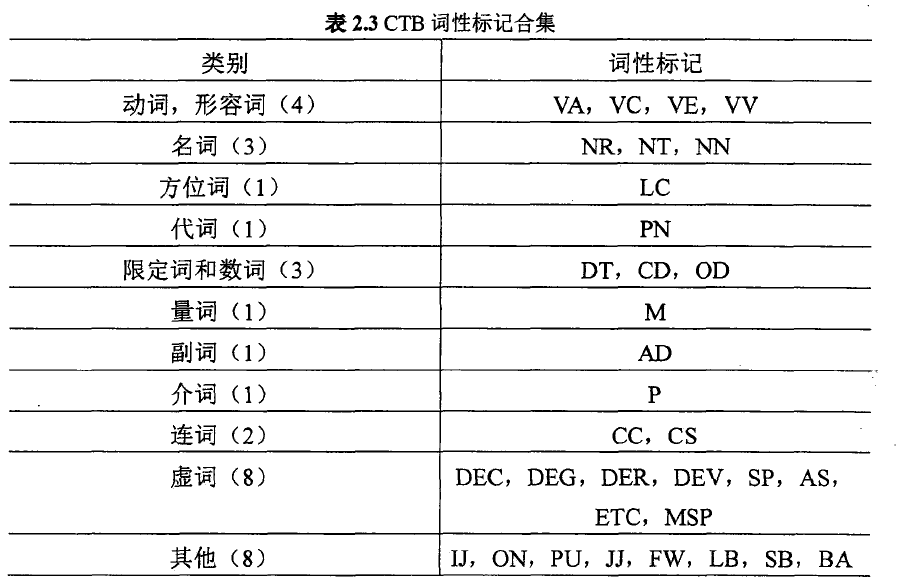
目前业界对于中文词性标注还没有形成标准的规范,在各种词性标注的规范中,应用比较多的是CTB(Penn Chinese TreeBank) 规范和相应的数据集。CTB中规定的词性包括 11个大类别和 23个小类别,具体内容可以参考 的相关项目文档 ,如表 所示。
根据 CTB 标注规范, 给出一个标注示例如下:

基于统计学习的词性标注方法
中文词语没有形态的变化,所以就无法通过词的形态变化来判断词性。而汉语中的词语大多是多义词,兼类比较严重。因此,中文词性标注更要依赖语义环境,表达不同的目标点的相同词语,其词性一般是不一样的。所以,不能简单的用查词典的标注方法。
由于中文语言的特殊性,热门的标注词性的方法有基于统计的方法和基于规则的方法两种。对于第二种方法,由于中文语言的复杂多变性,建立相应的语言规则库需要丰富的专家知识和大量的人工工作,因此大多是大型的科研院所研宄这类方法。而第一种方法由于可以通过较低的成本获得高质量的数据集而渐渐得到研究学者们的青睐,并成为比较主流的研究方法,主要有 n 元语法模型、条件随机场模型( CRFs )、最大熵模型(ME) 和隐马尔科夫模型( HHM )等。但是这种方法也有难以克服的缺点,就是其词性标注的效果严重依赖其使用的数据集的质量和规模。对于具有不同义项的词语,需要和当前上下文环境下该词的实际语义相结合才可以判断其词性。下例中“爱”既可以作为动词又可以作为名词。
对于具有不同义项的词语,需要和当前上下文环境下该词的实际语义相结合才可以判断其词性。下例中“爱”既可以作为动词又可以作为名词。

作为典型的基于统计的标注词性算法中,n元语法模型的大体思路是根据一定的策略,从构成句子的所有可能的词语标记序列中找出最合适的一串标记序列;
