中文分词技术
对一段文本进行语义分析,最终要落实到词语上,因为词语是能够表达一定意义的最小的能够独立活动的语言成分。由于汉语和英语在书写习惯上有很大的区别,英语中单词之间用空格隔幵,而汉语这是在句子之间用标点符号隔开,句子中的字词是连在一块的,没有特别的区分标记。因此,中文分词是研究语义分析的首要任务。
中文句子是由词语组成的一段连续的字符串,这里的词语不仅限于词汇,还包括汉语表述中不可避免的出现的一些非汉字字符,比如外文字符,阿拉伯数字和标点符号等。依据《现代汉语规范》中的定义,汉语中最小的语言处理单位是词语。中文分词站在语义信息处理的角度,依据某种规范将中文句子划分成最小独立单位的过程。划分结果要求词语结合符合中文语法习惯,分词算法稳定。
汉语中,词语的使用灵活,其定义和语义、语法以及应用场合、表达方式等第二章相关技术研究都有关。例如: “风景”是一个词语,但是风吹过来”不是词语。
比较有代表性的分词方法主要有三类:
- 第一类是通过匹配字典等预定义的规则对句子分词。
- 第二类是无监督学习方法,该方法主要通过词频统计、关联度分析等算法实现对中文句子分词。
- 第三类是有监督学习方法,主要是通过构造分类器和序列标注的方法实现分词。
其中,第一类使用灵活方便。但是由于基于字典的方法没有考虑词语的应用语境和句子的语义特点, 尚不能处理未登录词和多词冲突的情况。
没有被标注进词典的陌生词语称为未登录词。常见的未登录词主要有:地方名、特定人名、专业术语等, 可以通过扩充标注字典的放大处理这个问题。
多词冲突,是指某个字与其前后邻接的字组合,在词典中都可以查找到对应的词语, 如图 所示。 目前也有比较多的方法解决这个问题, 比如最少切分、 最大切分(包括前向切分、后向切分和前后组合切分)和全切分等算法。

基于两类分类器的中文分词方法
句子文本中每个字符(除了开头与结尾)都是左右相邻的, 因此需要结合上下文语境来判断两个字符是否可以结合成一个词语,而不能仅仅看相邻的字符。 同样的字符序列在不同的上下文语境中有时能组成有具体含义、有效的词语,有时需要切分开, 作为两个词语。
为了准确把握句子中的语境信息,我们可以用机器学习的思维来分析这个问题。如图 给定的字符序列, 中文分词问题可以转化成切分两个连续字符的问题。我们用“|”表示一个可能的切分,值为{0,1},1为切分,0为不切分;
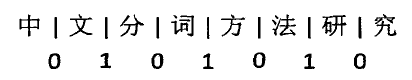
字符切割示意图对于每个可能的切割点,我们使用类似窗口概念的固定长度的滑块来获取相关的上下文信息。将滑块窗口中内容作为处理样本 取值作为类别判定结果 , 这样可以将中文分词作为二分类问题。

上面这种切分方法也有自己的缺陷,算法的前提假设是每个窗口中的潜在切分点是相互独立的,可以独立切分。而在复杂多变的汉语句子中,并不是所有的句子都能满足这一前提条件。为了克服这个缺陷,需要适当的放大语义窗口, 以达到更好的效果。
基于字标记的中文分词方法
目前,序列标注算法以其独特的优势成为热门的研宄算法,该算法不需要词典,采用字词的序列标注算法来解决中文分词问题,也不会出现未登录词和多个词语冲突的问题。xue根据每个字在词语中的位置做一个标记,通过基于字的标记方法解决标注问题。该方法主要标记左字、右字、中字和单字四种类型,peng也从序列标记的角度出发解决分词后采用最大熵模型算法得到分词结果。 问题 ,采用的是条件随机场模型算法,与最大熵模型相比,取得了更好的分词效果。
为了用序列标记方法解决中文分词问题,首先用{B, M, E, S}分别标记词语中的{开始词, 中间词,结束词,单字词}。例如: 句子“自然语言处理是计算机科学领域与人工智能领域中的一个重要部分,也是人工智能中最为困难的问题之一。 转化为以字为单位的标注序列如图所示。

标注示意图标注序列之后,我们还需要建立一个特征模板,用于抽取特征。其中特征模板的好坏会影响学习的效果;

根据标记序列, 在给定文本的每个位置上先用特征模板按顺序做特征抽取, 即可获得文本的所有特征。 比如序列“计算机科学领域”对应的标记序列为“BMEBEBE”, 假设当前分析的字符是“机”, 则根据“X[0]Y[0]“特征为“机|E”,而根据“X[-1]X[0]X[1]Y[0]”特征模板抽取的 ”抽取的词语特征为"算机科|B” 。以此类推,最后通过釆用机器学习的方法选取最合适的特征模板作为分词结果。
基于无监督学习的中文分词方法
若干字符搭配在一起构成词语,这种关系一般是比较固定的。所以相邻字符在句子段落中出现的频率可以作为反应其是否构成词语的概率。由此,可以通过统计语料中相邻字符出现的频率作为改词认定的概率,其值体现了这两个字符之间结合的密切程度, 当该值超过预设值时, 判定其可以组合为词语。
这种方法的优点是计算过程中只需要统计语料中字符出现的频率,不需要辅助字典,不需要对语料进行标注,实现起来比较简单。在实际应用中,该方法会经常将一些助词结构如“有的”、“中的”等误判为一个词语,这是因为这些词在曰常用语中经常出现。要解决这个问题,需要改进这种单纯用统计的方法, 比如可以增加一个词典,将常用、易误判的词语放在词典中,标注词性时排除词典中的词语组合。