data-connection
data-connection
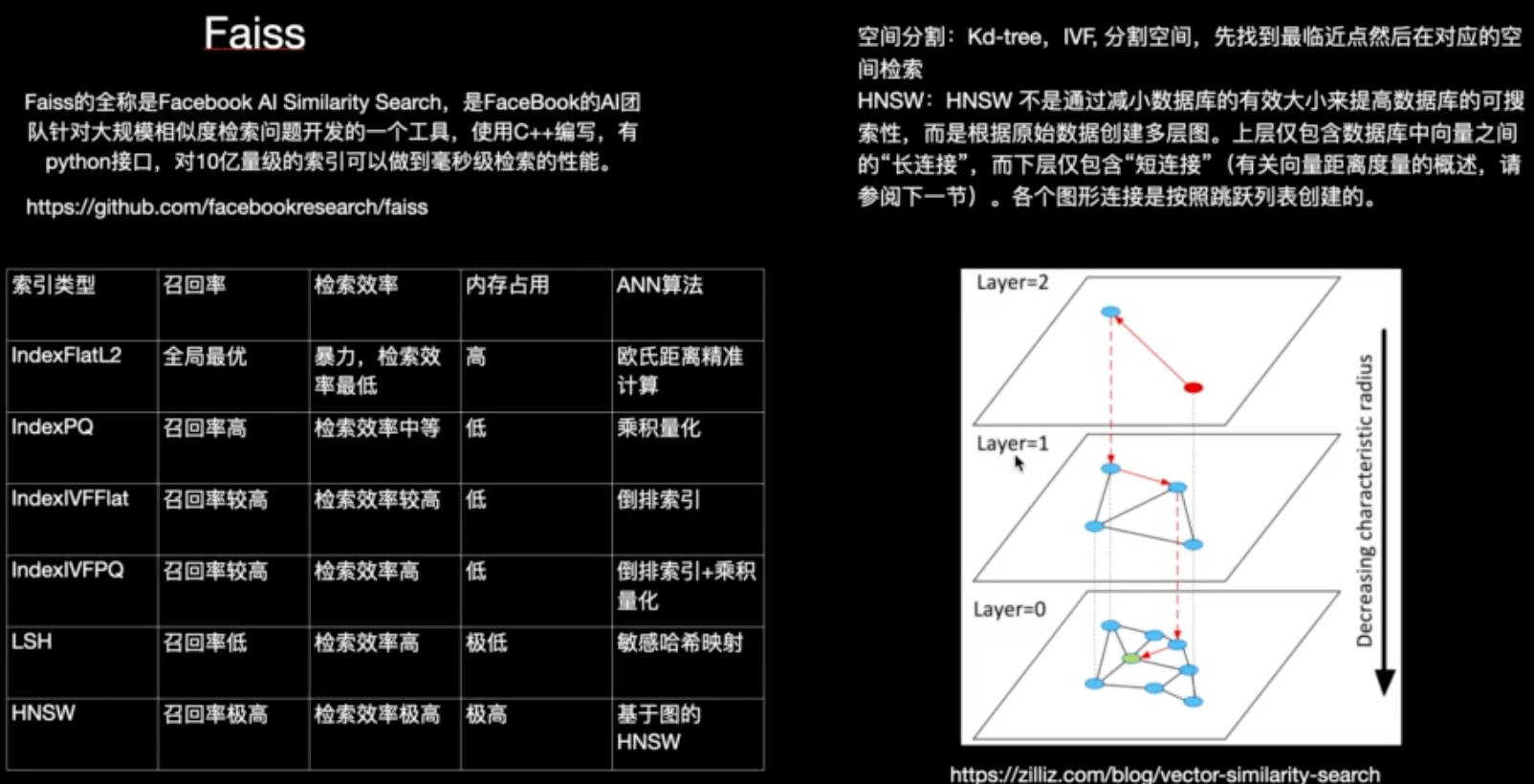
这块主要介绍大模型中如何使用数据,向量数据库大家都听说过。先把文本资料存储到向量数据库,然后查询搜索内容相关的向量数据知识作为上下文输入;
- 这里主要介绍这些资料数据如何转换成向量存储,如何在获取出来;
许多 LLM 应用程序需要用户特定的数据,这些数据不属于模型的训练集。
LangChain 为您提供了加载、转换和查询数据的基础构件:
- 文档加载器(Document loaders):从许多不同的源加载文档
- 文档转换器(Document transformers):分割文档、删除冗余文档等
- 文本嵌入模型(Text embedding models):将非结构化文本转换为浮点数列表
- 向量存储(Vector stores):存储和检索嵌入数据
- 检索器 (Retrievers):查询您的数据
文档加载器
这一步主要是读取数据源,一般是文本数据源;
langchain提供了多种常用的文档加载器,包括
- JSONLoader
- JSONLinesLoader
- TextLoader
- CSVLoader
文档转换器
这部分主要是解析读取的文本数据,主要是分词工作;学过NLP基本知识就知道,第一步处理文本就是分词;分词有不同的算法,要保证分词尽可能全,尽可能准确;
langchain提供的分析算法:
- CharacterTextSplitter, 按照分隔符分割,超出快最大长度就分开;
- 参数有分隔符,块最大长度,块重叠字符数
- RecursiveCharacterTextSplitter,重叠滑动窗口分词
- 参数有块最大长度,块重叠字符数,滑动窗口来分词;,分制词默认是[’\n\n’, ‘\n’, ’ ‘],尽可能保持所有段落(然后句子,然后单词)在一起,因为它们在语义上通常是最相关的文本片段
import { Document } from "langchain/document";
import { RecursiveCharacterTextSplitter } from "langchain/text _splitter";
const text = `Hi.I'n Harrison.How? Are? You?Okay then
This is a weird text to write, but gotta test the splittingged some how.
Bye!-H.*`;
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 100,
chunkOvErlap: 20,
};
const docOutput = await splitter.splitDocuments(||
new Document({ pageContent: text }),
]);
-output-
Document 1
pageContent: "Hi.I'm Harrison.How? Are? You?Okay then f f f f.", metadata: { loc: [Object] }
Document 1
pageContent: `This is a weird text to write, but gotta test the splittinggag some how.\n
+ Bye!-H. `
netadata: { loc: [Object] }
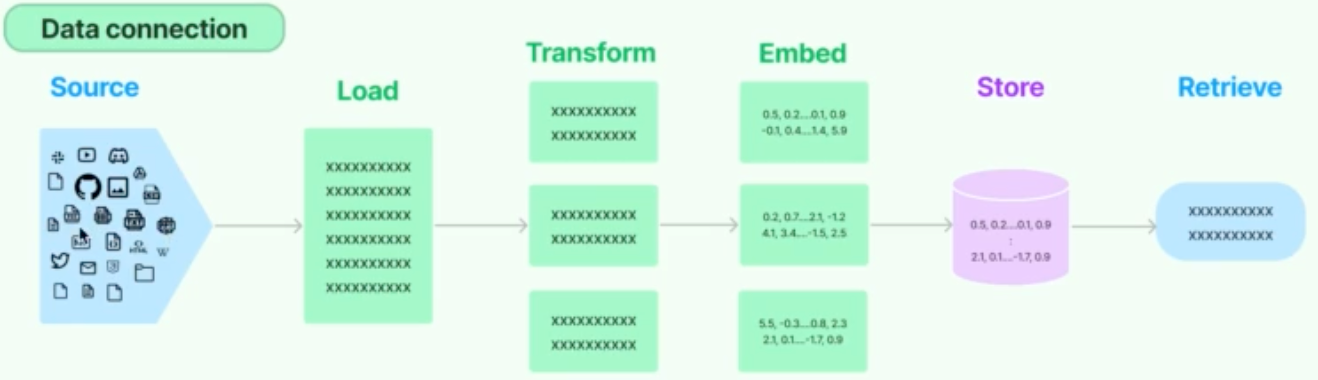
文本嵌入
embeding的过程主要是将上步骤的分词转化为词向量数据,这里需要注意最好用和大模型一样的词向量库,这样后面再查询关联性的时候才能保证和大模型是一样的关联度;
- 用大模型词向量库查询分词的向量表示,将向量存入到本地向量库中;
- 这个如果不用大模型的词向量,也可以自己用transfromer训练自己的词向量库,但是查询的时候用同样的词向量库计算查询此即可;建议可以用Sentence Transformer;
- 下次用户查询时,先采用通用的过程对用户输入分词,查询词向量,然后在本地向量库中找到关联性强的数据作为上下文,然后输入到大模型;
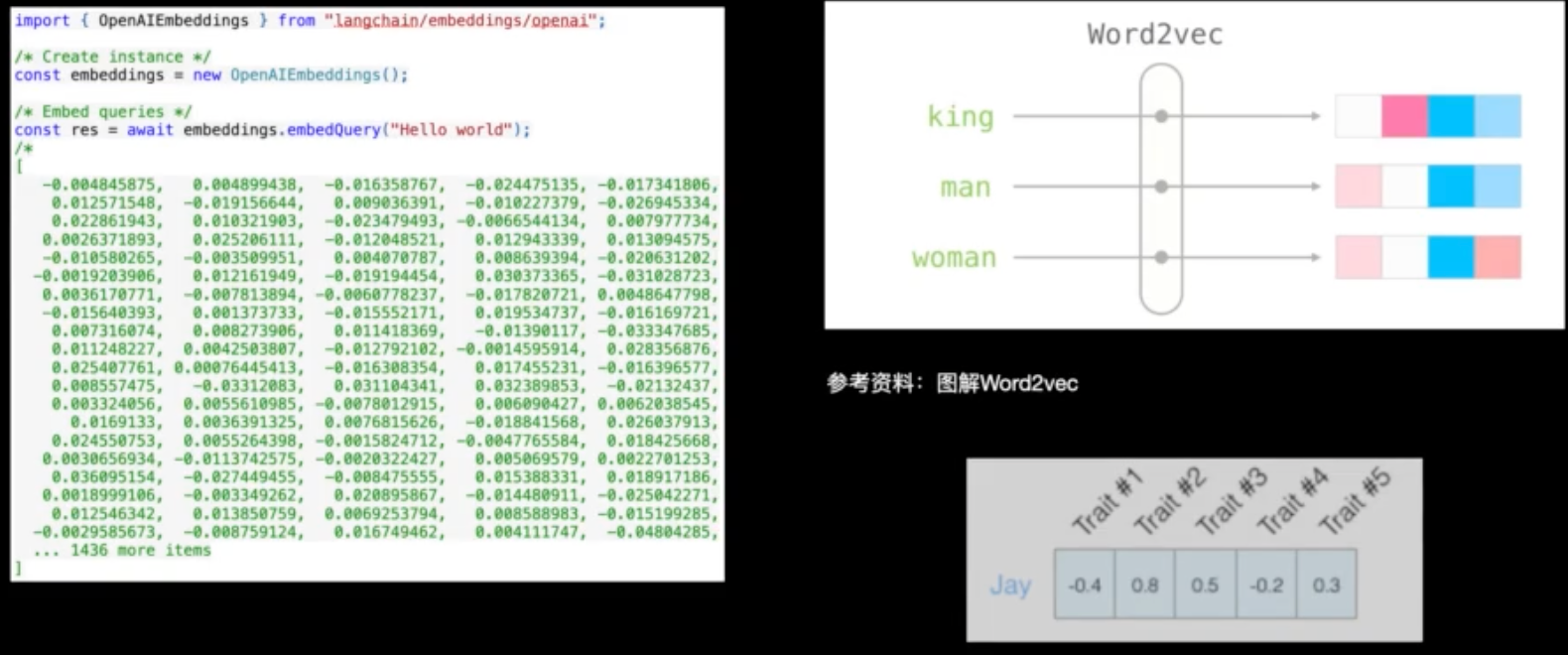
向量运算过程示例:

向量存储
这里主要介绍下Faiss向量数据库;